What Is Machine Learning? How Computers Learn From Data
Machine learning sounds like a machine is learning the way a person does.
It is not.
A person learns through experience, judgment, memory, context, and reasoning. A machine learning system learns in a narrower way. It studies data, finds patterns, and uses those patterns to make predictions, classifications, recommendations, or decisions on new information.
That is why machine learning matters.
Instead of programming every rule by hand, people can train a model on examples. The model does not need to be told every possible signal of spam, fraud, customer churn, or equipment failure. It can learn useful patterns from data and apply them to cases it has not seen before.
This guide explains what machine learning means, how it works, what a model actually is, where machine learning is used, and why its results still need testing, context, and human judgment.
Key Takeaways
- Machine learning is a method within artificial intelligence that helps systems learn patterns from data instead of relying only on hand-coded rules.
- A machine learning model is trained on examples, then used to make predictions, classifications, recommendations, or decisions on new information.
- The quality of machine learning depends heavily on the quality of the data, the clarity of the task, and the way the model is tested.
- Supervised learning, unsupervised learning, and reinforcement learning are three major types of machine learning.
- Deep learning is a subset of machine learning, not a separate replacement for it.
- Machine learning can be powerful, but it can also fail when data is biased, incomplete, outdated, mislabeled, or poorly matched to the real-world situation.
- A machine learning prediction should not be treated as certainty. It should be judged by context, evidence, and the cost of being wrong.
Affiliate Disclosure: Some links on our site are affiliate links. This means that if you click one of these links and make a purchase, we may earn a small commission at no additional cost to you.

What Machine Learning Actually Means
Machine learning is a way for computer systems to learn patterns from data.
It is part of artificial intelligence, but it is not the same as artificial intelligence as a whole. AI is the broader field. Machine learning is one of the main methods used to build AI systems that can adapt based on examples.
The word “learning” can be misleading.
A machine learning system does not learn through understanding, experience, or judgment the way a person does. It learns by adjusting a model during training so the model can recognize useful patterns in data.
Those patterns can then be used for different tasks.
A model might predict whether a customer is likely to cancel. It might classify an email as spam. It might recommend a product, flag an unusual transaction, rank search results, or detect a defect in an image.
The system is not following a hand-written rule for every possible case.
It is using patterns learned from previous examples to respond to new information.
That is the core idea behind machine learning: instead of telling the computer every rule, you train it with data so it can find patterns and apply them to new situations.

The Difference Between Rules And Patterns
Traditional software usually starts with rules.
A person writes instructions that tell the system what to do. If this happens, do that. If a condition is met, return a specific result. This works well when the logic is clear, stable, and easy to describe.
Machine learning is different because it starts with examples.
Instead of writing every rule by hand, people give the system data related to the task. The model looks for patterns in that data and uses those patterns to make predictions or classifications on new inputs.
A spam filter is a simple way to see the difference.
A rule-based spam filter might block emails that contain certain words, suspicious links, or specific formatting. That can help, but it is easy to miss spam that avoids those rules. It can also block legitimate emails that happen to match them.
A machine learning spam filter can learn from many examples of spam and legitimate messages. Over time, it may notice patterns that would be difficult to capture with fixed rules alone, such as combinations of wording, sender behavior, formatting, timing, and user feedback.
That is the advantage of machine learning.
It can handle patterns that are too subtle, too numerous, or too changeable to code manually.
But the tradeoff is control.
Rules are easier to inspect because someone wrote them directly. Machine learning models can be harder to interpret because their behavior comes from patterns learned during training.
That does not make machine learning better or worse than traditional programming.
It means each approach fits a different kind of problem.
What A Machine Learning Model Is
A machine learning model is the part of the system that stores what has been learned from data.
It is not a spreadsheet of memorized answers.
It is not a list of fixed instructions.
A model is a mathematical structure that has been trained to recognize patterns and apply them to new inputs.
For example, a model trained to detect fraud may learn that certain combinations of transaction amount, location, timing, device behavior, and account history are more likely to be suspicious. When a new transaction appears, the model compares it against the patterns it learned and produces an output.
That output might be a prediction, score, label, ranking, or recommendation.
The model does not “know” the answer in the human sense. It estimates the most likely result based on its training and the information it receives.
This is why the training process matters so much.
A model trained on strong, relevant data has a better chance of producing useful results. A model trained on weak, biased, outdated, or incomplete data may learn patterns that do not hold up in real use.
The model is the engine of machine learning, but it is only as useful as the task, data, training, testing, and oversight around it.
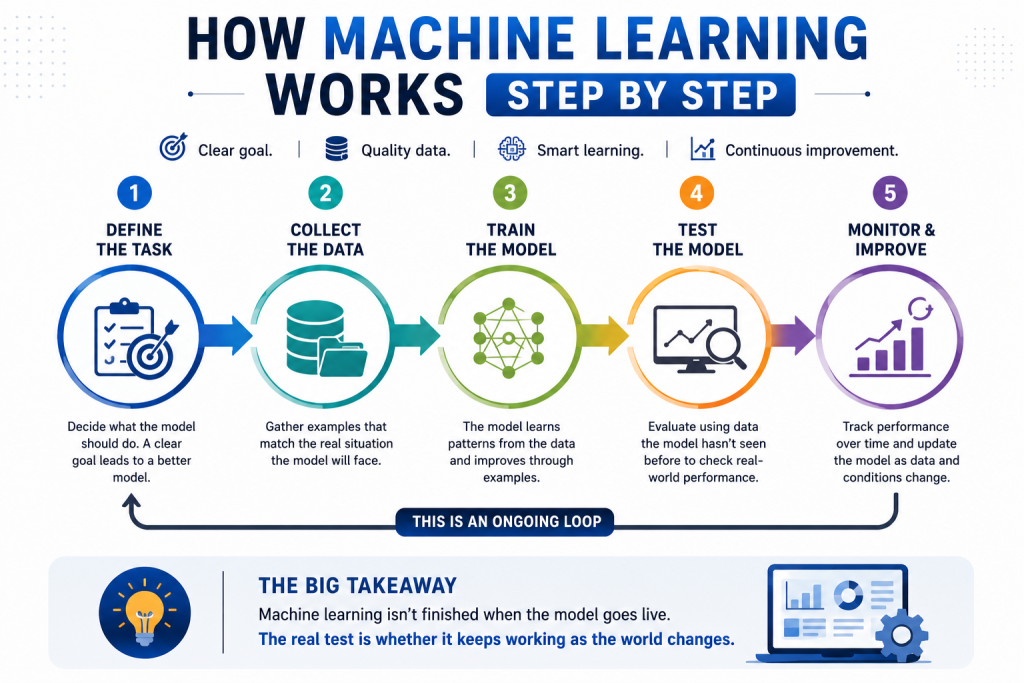
How Machine Learning Works Step By Step
Machine learning usually follows a clear process.
The exact workflow can vary, but the basic path is the same: define the problem, train the model, test the result, and keep checking performance after the system is used.
- Define The Task
The first step is deciding what the model is supposed to do.
It might need to predict customer churn, classify support tickets, detect fraud, recommend products, forecast demand, or identify defects in images.
A vague task leads to a weak model.
A clear task gives the system a specific target.
- Collect The Data
The model needs examples related to the task.
For a spam filter, that data might include past emails labeled as spam or legitimate. For a demand forecast, it might include sales history, seasonality, pricing, inventory, and market signals.
The data should match the real situation the model will face later.
- Prepare The Data
Raw data is rarely ready to use.
It may contain missing values, duplicates, errors, inconsistent labels, irrelevant fields, or sensitive information that needs to be handled carefully.
Preparing the data helps the model learn from the right signals instead of noise.
- Train The Model
Training is where the model learns patterns from the data.
The model adjusts its internal settings so its outputs become closer to the desired result.
In simple terms, it keeps learning from examples until it becomes better at the task it was given.
- Test The Model
A model should be tested on data it did not use during training.
This matters because the goal is not to memorize old examples. The goal is to perform well on new information.
Testing helps show whether the model has learned useful patterns or simply fit itself too closely to the training data.
- Use The Model On New Inputs
Once the model performs well enough, it can be used on new cases.
It may assign a risk score, recommend an item, classify a document, predict a number, or flag something for review.
At this point, the model is applying learned patterns to information it has not seen before.
- Monitor Performance Over Time
Machine learning does not end when the model is deployed.
Data changes. Customer behavior changes. Fraud tactics change. Markets change. Equipment ages. Language shifts.
A model that worked well at launch can become less reliable later.
That is why machine learning systems need monitoring, review, and updates. The real test is not whether a model works once. It is whether it continues to work when the world around it changes.
The Main Types Of Machine Learning
Machine learning is not trained in only one way.
The right training approach depends on the problem, the data available, and the kind of output the system needs to produce.
Most introductory explanations focus on three main types: supervised learning, unsupervised learning, and reinforcement learning.
Supervised Learning
Supervised learning uses labeled examples.
That means the training data includes both the input and the correct answer.
For example, a model trained to identify spam might receive many emails already labeled as “spam” or “not spam.” A model trained to estimate home prices might receive property details along with actual sale prices.
The model studies those examples and learns patterns that connect the inputs to the labels.
Then it uses those patterns on new information.
Supervised learning is commonly used for classification and prediction tasks, such as fraud detection, credit risk scoring, image classification, sales forecasting, and customer churn prediction.
Unsupervised Learning
Unsupervised learning works with data that does not include labeled answers.
Instead of being told what each example means, the model looks for structure on its own.
It may group similar customers, identify unusual transactions, find hidden patterns in documents, or organize large datasets into clusters.
This type of machine learning is useful when the goal is exploration.
The system is not being asked to predict one correct answer. It is being used to discover patterns that may help people understand the data better.
Reinforcement Learning
Reinforcement learning is based on rewards and penalties.
The system learns by taking actions and receiving feedback. Actions that lead to better outcomes are rewarded. Actions that lead to worse outcomes are discouraged.
This approach is often used in games, robotics, control systems, simulation environments, and optimization problems.
The model is not learning from labeled examples in the same way supervised learning does. It is learning through trial, feedback, and adjustment.
Reinforcement learning can be powerful, but it also needs careful design. If the reward is poorly defined, the system may learn behavior that technically scores well but does not match what people actually wanted.
What Machine Learning Is Used For
Machine learning is useful when there is enough data to learn from and a clear task to improve.
One common use is fraud detection.
Banks, payment companies, and online platforms can use machine learning to identify unusual patterns in transactions, account behavior, locations, devices, or timing. The model may not decide the final outcome by itself, but it can flag activity that deserves review.
Recommendation systems are another familiar example.
Streaming platforms, online stores, search engines, and social media feeds use machine learning to predict what a person may want to watch, buy, read, or click next. These systems look for patterns in behavior and compare them with similar users, products, or content.
Machine learning also supports forecasting.
A business might use it to estimate demand, plan inventory, predict customer churn, or anticipate equipment failure. In these cases, the goal is not perfect certainty. The goal is a useful prediction that helps people make better decisions.
In healthcare, machine learning can support tasks like analyzing medical images, organizing patient records, or identifying risk patterns. These uses require strong oversight because errors can affect real people in serious ways.
Customer service teams may use machine learning to route tickets, detect sentiment, suggest replies, or identify urgent issues.
Operations teams may use it to classify documents, monitor systems, detect anomalies, or improve scheduling.
Software teams may use it to search code, suggest fixes, detect bugs, or assist with testing.
The pattern across all these examples is simple.
Machine learning helps when a system needs to find patterns in more information than people can review manually, or when the same type of decision must be made many times.
It is not valuable because it sounds advanced.
It is valuable when the prediction, classification, ranking, or recommendation improves the work being done.
What Makes Machine Learning Work Well
Machine learning works best when the problem is clearly defined.
A model needs a specific job. Predicting customer churn is clearer than “understanding customers.” Detecting suspicious transactions is clearer than “improving security.” Classifying support tickets is clearer than “making service better.”
A clear task gives the model a target.
The next requirement is relevant data.
The data should reflect the situation where the model will actually be used. A model trained on old, incomplete, or mismatched data may perform well in testing but fail when it meets real users, new behavior, or changing conditions.
Quality matters too.
For supervised learning, labels need to be accurate. If the training examples are mislabeled, the model may learn the wrong relationships. If important cases are missing, it may perform poorly on the people, products, transactions, or situations that were underrepresented.
Testing is another part of the foundation.
A model should be evaluated on data it did not use during training. That helps show whether it learned patterns that apply to new cases, rather than memorizing the examples it already saw.
Good machine learning also requires monitoring after deployment.
The world changes. Customer behavior shifts. Fraud tactics evolve. Market conditions move. Equipment ages. Language changes. A model that worked well at launch can become less reliable over time.
Human review matters when the stakes are high.
A model can provide a prediction, score, label, or recommendation. That output may be useful, but it should be judged in context. The more serious the consequence, the stronger the review process should be.
Machine learning works well when the task is clear, the data is strong, the testing is honest, and the people using the system understand what the model can and cannot decide.
Where Machine Learning Goes Wrong
Machine learning can fail even when the model looks accurate in testing.
One common problem is biased data.
If the training data reflects unfair, incomplete, or distorted patterns, the model may learn those patterns and repeat them. This can be especially harmful when machine learning is used in areas like hiring, lending, healthcare, education, insurance, or public services.
Incomplete data creates another weakness.
A model can only learn from the examples it receives. If important groups, situations, edge cases, or time periods are missing, the model may perform poorly when those cases appear in real life.
Outdated data can cause similar problems.
A fraud detection model trained on old behavior may miss new tactics. A demand forecast based on past buying patterns may fail when the market changes. A customer model may become less useful when user behavior shifts.
Machine learning can also overfit.
Overfitting happens when a model performs well on training data but struggles with new data. The model has learned the old examples too closely instead of learning patterns that generalize.
Data leakage is another testing problem.
It happens when information from outside the proper training process slips into the model or evaluation. The result can make performance look better than it really is.
Even when the data is strong, the objective can be wrong.
A model may optimize for clicks, speed, cost, or accuracy in a way that creates bad outcomes elsewhere. A recommendation system that maximizes engagement may promote low-quality content. A service model that prioritizes speed may route complex cases poorly.
The deeper issue is that machine learning does not understand the goal the way people do.
It optimizes for the target it was given.
That is why predictions should not be treated as certainty, and model outputs should not replace judgment in high-stakes decisions.
Machine learning goes wrong when people confuse a useful pattern with a complete answer.
Machine Learning Vs Deep Learning Vs Neural Networks
Machine learning, deep learning, and neural networks are often discussed together because they are connected.
They should not be used as if they mean the same thing.
The easiest way to understand the relationship is to move from broad to specific.
Artificial Intelligence
└── Machine Learning
└── Deep Learning
└── Neural Networks
Machine Learning Is The Broader Method
Machine learning is the broader category.
It includes methods that allow computer systems to learn patterns from data and use those patterns on new inputs.
A machine learning system might predict customer churn, classify emails, detect fraud, recommend products, or forecast demand. It does not need to use deep learning to do those things.
That matters because machine learning is not one single technique.
Some machine learning models are relatively simple. Others are highly complex. The right method depends on the task, the data, and how much accuracy, speed, interpretability, or oversight the use case requires.
Deep Learning Is A Subset Of Machine Learning
Deep learning is a more specialized branch of machine learning.
It uses neural networks with multiple layers to learn complex patterns from large amounts of data.
This is why deep learning is often used for tasks such as image recognition, speech recognition, language processing, and large-scale generative AI.
The tradeoff is that deep learning usually requires more data, more computing power, and more careful evaluation than simpler machine learning methods.
It can be powerful, but it is not automatically the right choice for every problem.
Neural Networks Are A Model Structure
A neural network is a structure used to build some machine learning models.
It is made of connected layers that process information and adjust during training.
In simple terms, the network receives an input, passes information through layers, and produces an output. During training, the connections inside the network are adjusted so the output becomes more useful for the task.
Neural networks are central to deep learning, but they are not the whole of machine learning.
Many machine learning systems use other methods that do not rely on deep neural networks.
Why The Difference Matters
These distinctions help keep AI claims honest.
A company may say it uses AI, but that does not tell you whether the system uses machine learning, deep learning, neural networks, or another approach.
A simple predictive model may be more useful than a complex neural network if the task is narrow, the data is limited, or the decision needs to be explained clearly.
A deep learning system may be a better fit when the data is large, complex, and difficult to describe with simple rules.
The practical question is not which term sounds most advanced.
The better question is which method fits the problem, the data, the risks, and the need for human understanding.
How To Evaluate A Machine Learning Claim
A machine learning claim should be judged by the problem it solves, not by how advanced it sounds.
The first question is simple:
What is the model trying to predict, classify, rank, detect, or recommend?
That question matters because machine learning only makes sense when the task is clear. A vague claim like “our platform uses machine learning” does not tell you much. A clearer claim explains what the model does and how its output improves a decision or workflow.
The next question is about data.
What was the model trained on?
A model trained on strong, relevant data has a better chance of producing useful results. A model trained on weak, incomplete, outdated, or biased data may still produce outputs, but those outputs may not hold up in real use.
Testing matters just as much.
A model should be evaluated on new data, not only on the examples it learned from during training. That helps show whether the model can generalize beyond the data it already saw.
The result also needs context.
A prediction is not a fact. A risk score is not a final decision. A recommendation is not proof that the next action is correct.
Machine learning outputs should be treated as signals that need judgment, especially when the stakes are high.
The cost of being wrong should shape how much trust the model gets.
A mistaken product recommendation may be annoying. A mistaken fraud flag, medical alert, hiring score, insurance decision, or loan assessment can have serious consequences.
The final question is about responsibility.
Who reviews the output?
Who can override the system?
Who is accountable if the model is wrong?
A machine learning system is easier to trust when its purpose is clear, its data is relevant, its performance is tested honestly, and its outputs are reviewed at the right level.
Conclusion
Machine learning is not about computers learning like people.
It is about training systems on data so they can find patterns and apply those patterns to new information.
That shift is what makes machine learning useful. Instead of writing every rule by hand, people can define a task, provide examples, train a model, and test whether the model performs well outside the data it already saw.
The strength of machine learning depends on the system around it.
A clear problem, relevant data, honest testing, and ongoing monitoring matter as much as the model itself. Weak data, vague goals, poor labels, or changing real-world conditions can turn a promising model into an unreliable one.
Machine learning is powerful when it helps people predict, classify, detect, recommend, or decide with more evidence.
It becomes risky when its outputs are treated as certainty.
The best way to understand machine learning is to see it as a pattern-learning method inside artificial intelligence. It can improve decisions and automate complex tasks, but it still needs context, review, and human responsibility.

Frequently Asked Questions
What Is Machine Learning In Simple Terms?
Machine learning is a way for computers to learn patterns from data.
Instead of following only hand-written rules, the system is trained on examples and uses what it learns to make predictions, classifications, recommendations, or decisions.
Is Machine Learning The Same As AI?
No. Artificial intelligence is the broader field.
Machine learning is one method within AI. It helps systems improve at specific tasks by learning from data.
What Is A Machine Learning Model?
A machine learning model is the part of the system that stores the patterns learned during training.
Once trained, the model can use those patterns to respond to new inputs, such as predicting a result, assigning a label, or making a recommendation.
What Are The Main Types Of Machine Learning?
The three main types are supervised learning, unsupervised learning, and reinforcement learning.
Supervised learning uses labeled examples. Unsupervised learning finds patterns in unlabeled data. Reinforcement learning improves through rewards, penalties, and feedback.
What Is Supervised Learning?
Supervised learning trains a model with examples that already include the correct answer.
For example, a spam detection model may learn from emails labeled as spam or not spam, then use those patterns to classify new emails.
What Is Unsupervised Learning?
Unsupervised learning looks for patterns in data without being given labeled answers.
It is often used for grouping similar items, finding unusual behavior, or discovering patterns that people may not have defined in advance.
What Is Reinforcement Learning?
Reinforcement learning trains a system through feedback.
The system takes actions, receives rewards or penalties, and adjusts its behavior to improve the outcome over time.
What Is The Difference Between Machine Learning And Deep Learning?
Machine learning is the broader category.
Deep learning is a subset of machine learning that uses layered neural networks to learn complex patterns, often from large amounts of data.
Can Machine Learning Make Mistakes?
Yes. Machine learning can make mistakes when the data is biased, incomplete, outdated, mislabeled, or poorly matched to the real-world task.
A model can also fail when conditions change after it has been trained.
Does Machine Learning Need Human Oversight?
Yes, especially when the stakes are high.
Machine learning can support decisions, but people still need to define the task, review the output, monitor performance, and take responsibility for how the system is used.
Leave a Reply